📜 | Anatomie du protocole HTTP
Cette partie n'est pas à apprendre par cœur, mais elle constitue un élément principal de la compréhension du monde du WEB. La compréhension des différents termes évoqués est nécessaire.
Dans le cadre du développement web, le protocole HTTP (HyperText Transfer Protocol) joue un rôle central en permettant la communication entre les navigateurs web (clients) et les serveurs. Lorsqu'un utilisateur accède à une page web ou interagit avec une application en ligne, une série de requêtes et réponses HTTP sont échangées entre le client et le serveur. Comprendre l’anatomie d'une requête HTTP est essentiel pour diagnostiquer des problèmes, optimiser des applications web, et développer des services API efficaces.
Les composantes d'une requête HTTP
Une requête HTTP se divise en plusieurs parties distinctes, chacune ayant un rôle spécifique.
Voici un diagramme pour faciliter la compréhension tout au long de l'explication :
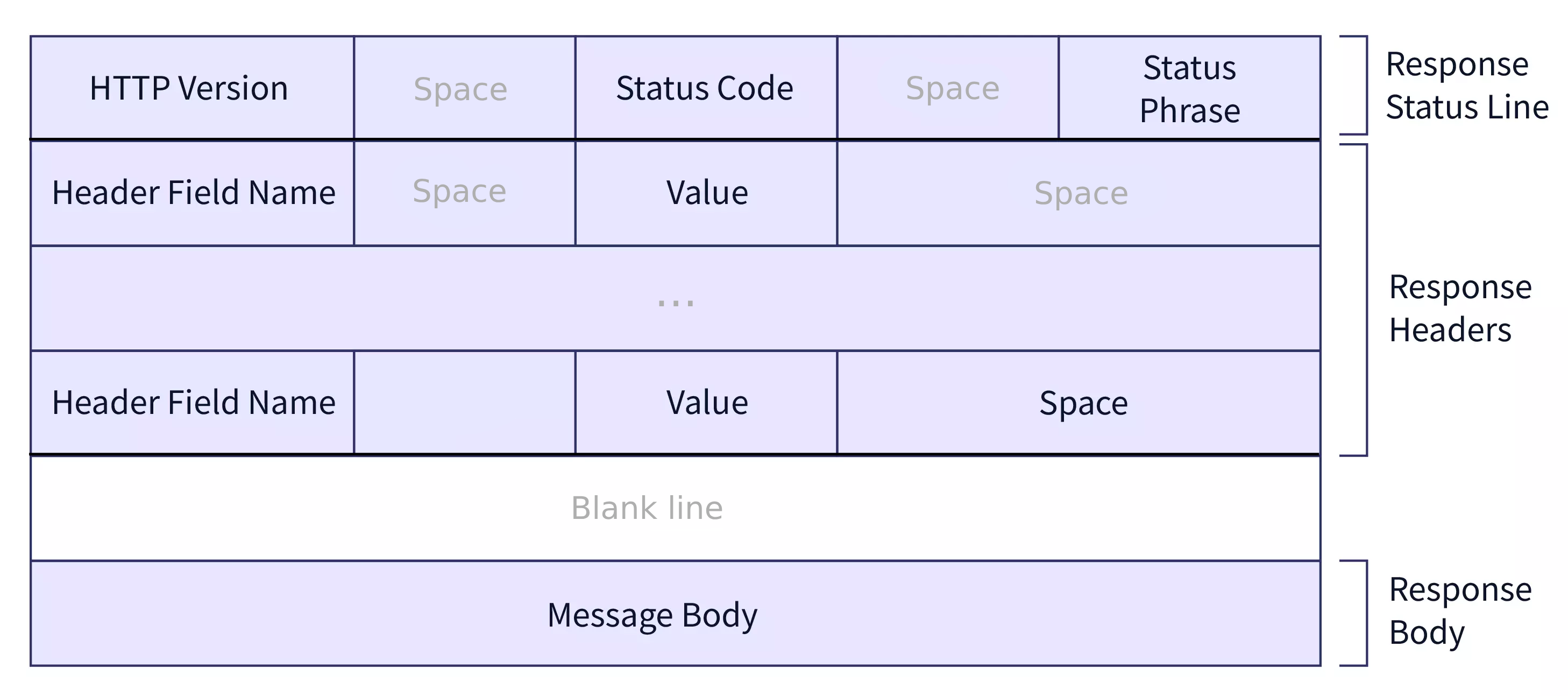
Ligne de requête (Request Line)
La ligne de requête est la première ligne de la requête HTTP. Elle contient trois informations clés :
-
Méthode HTTP : elle spécifie l'action à réaliser sur la ressource demandée. Les méthodes les plus courantes sont :
GET: pour récupérer une ressource (lecture).POST: pour envoyer des données au serveur (souvent pour créer ou mettre à jour une ressource).PUT: pour remplacer ou mettre à jour une ressource existante.DELETE: pour supprimer une ressource.PATCH: pour mettre à jour partiellement une ressource.
-
URI (Uniform Resource Identifier) : c’est l’adresse de la ressource demandée, souvent appelée chemin ou endpoint. Par exemple,
/articles/42fait référence à l'article numéro 42. -
Version du protocole HTTP : généralement
HTTP/1.1ouHTTP/2, cette information précise quelle version du protocole est utilisée.
Exemple :
GET /articles/42 HTTP/1.1
En-têtes de requête (Headers)
Les en-têtes de requête fournissent des informations supplémentaires sur la requête, telles que le type de contenu envoyé, les autorisations nécessaires, ou encore des informations sur le client. Chaque en-tête est une paire clé-valeur.
Les en-têtes courants incluent :
- Host : l’adresse du serveur (ex :
www.example.com). - User-Agent : informations sur le client, comme le type de navigateur utilisé.
- Accept : spécifie le type de contenu que le client peut accepter (ex :
text/html,application/json). - Content-Type : indique le type de données envoyées dans le corps de la requête (utile pour
POSTouPUT, ex :application/json). - Authorization : contient les informations d'authentification.
Exemple :
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: application/json
Corps de la requête (Body)
Le corps de la requête est une partie optionnelle qui contient les données envoyées au serveur, par exemple lors d'une requête POST ou PUT. Ces données peuvent être de divers formats (JSON, XML, formulaire encodé, etc). Pour une requête GET, le corps de la requête est généralement absent car les données sont passées dans l'URI (via des paramètres de requête).
Exemple (dans une requête POST) :
{
"title": "Nouvel Article",
"content": "Contenu de l'article..."
}
Le cycle d'une requête HTTP
Lorsque le client (le navigateur ou une application) envoie une requête HTTP, voici les étapes principales qui se déroulent :
- L'utilisateur interagit avec l'interface (par exemple en cliquant sur un lien ou un bouton de soumission de formulaire).
- Le navigateur envoie une requête HTTP au serveur spécifié, contenant la ligne de requête, les en-têtes et, dans certains cas, un corps de requête.
- Le serveur reçoit la requête, l'interprète, et effectue les actions nécessaires (récupérer des données depuis une base, effectuer des calculs, etc.).
- Le serveur envoie une réponse HTTP au client, contenant les données demandées ou un message d’erreur si la requête ne peut être traitée.
- Le navigateur affiche le résultat à l'utilisateur sous forme de page web, d'alerte, ou toute autre représentation.
Exemple complet d'une requête HTTP
Prenons un exemple où un utilisateur cherche à récupérer un article depuis un serveur via une requête GET.
Requête HTTP
GET /articles/42 HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: application/json
Ici, le client demande l'article numéro 42 au serveur www.example.com. Le client indique qu'il souhaite recevoir les données au format JSON grâce à l'en-tête Accept.
R�éponse HTTP du serveur
En retour, le serveur pourrait répondre avec :
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 126
{
"id": 42,
"title": "Nouvel Article",
"content": "Voici le contenu de l'article."
}
Dans cet exemple :
- Le code de statut
200 OKsignifie que la requête a réussi. - Le type de contenu est spécifié comme
application/json, ce qui correspond à la demande du client. - Le corps de la réponse contient les détails de l'article en format JSON.
Les méthodes HTTP les plus courantes
Les méthodes HTTP, également appelées verbes HTTP, spécifient le type d'action à effectuer sur une ressource donnée. Voici un aperçu des méthodes les plus utilisées :
-
GET : Utilisé pour récupérer des informations d'une ressource. Une requête
GETne devrait pas modifier l'état de la ressource. -
POST : Utilisé pour envoyer des données au serveur, par exemple pour créer une nouvelle ressource. Il est souvent utilisé pour soumettre des formulaires ou des données JSON.
-
PUT : Utilisé pour remplacer entièrement une ressource existante avec les données fournies. Il s'agit d'une opération idempotente, ce qui signifie que l'application répétée de la requête ne modifie pas davantage la ressource.
-
PATCH : Semblable à
PUT, mais il est utilisé pour mettre à jour partiellement une ressource. -
DELETE : Utilisé pour supprimer une ressource sur le serveur.
En-têtes importants dans une requête HTTP
Certains en-têtes jouent un rôle important dans le traitement des requêtes HTTP :
-
Cache-Control : Gère le comportement de mise en cache des ressources. Par exemple, il peut indiquer au navigateur s’il doit stocker une copie de la ressource et pendant combien de temps.
-
Authorization : Utilisé pour transmettre des informations d'authentification, comme un jeton d'accès dans les services sécurisés.
-
Cookie : Utilisé pour stocker et envoyer des informations liées à une session utilisateur ou à des préférences sur le site web.
Exemple complet
Voici un exemple plus complexe pour savoir à quoi peut ressembler une requête HTTP dans un cas réel :
POST /api/v1/users/create?notify=true&admin=false HTTP/1.1
Host: api.example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.e30.m5uXnxMlfz_mxCzMzRZZHY
Content-Type: application/json
Accept: application/json
User-Agent: Firefox/1.0.0
Cache-Control: no-cache
Pragma: no-cache
Content-Length: 245
{
"firstName": "John",
"lastName": "Doe",
"email": "john.doe@example.com",
"password": "SuperSecretPassword",
"roles": ["user", "editor"],
}
- Méthode HTTP :
POSTest utilisé ici pour créer une nouvelle ressource (un utilisateur). - Chemin de l'API :
/api/v1/users/createindique l'URL du endpoint.- Paramètres de requête :
?notify=true&admin=falseprécise que l'utilisateur doit être notifié et qu'il ne sera pas créé en tant qu'administrateur.
- Paramètres de requête :
- En-têtes HTTP (Headers) :
Authorization: Bearerest utilisé pour envoyer un token JWT (JSON Web Token) pour l'authentification.Content-Type: application/jsonindique que le corps de la requête est au format JSON.Accept: application/jsonsignifie que la réponse attendue doit également être au format JSON.User-Agentspécifie l'application qui envoie la requête.Cache-ControletPragmadésactivent la mise en cache.
- Corps de la requête (Body) : Un JSON qui contient les informations de l'utilisateur à créer.
Cette requête va ensuite être traitée par le back-end qui disposera alors de toutes ces informations.
Codes HTTP
La réponse d'une requête arrive avec un code de retour allant de 100 à 527. Le premier chiffre est utilisé pour spécifier une des cinq catégories de réponse :
- 1XX : information
- 2XX : succès
- 3XX : redirection
- 4XX : erreur client
- 5XX : erreur serveur
Les codes les plus courants sont :
- 200 : succès de la requête
- 201 : succès avec création de ressource
- 301 et 302 : redirection, respectivement permanente et temporaire
- 401 : utilisateur non authentifié
- 403 : accès refusé
- 404 : ressource non trouvée
- 500, 502 et 503 : erreurs serveur
Voir la liste complète des codes HTTP
Sécurité avec HTTPS
HTTPS (Hypertext Transfer Protocol Secure) est la combinaison du HTTP avec une couche de chiffrement TLS. HTTPS permet au visiteur de vérifier l'identité du site web auquel il accède, grâce à un certificat d'authentification émis par une autorité tierce, réputée fiable.
La TLS (ou SSL) fonctionne suivant un mode client-serveur. Il permet de satisfaire les objectifs de sécurité suivants :
- L'authentification du serveur
- La confidentialité des données échangées (ou session chiffrée)
- L'intégrité des données échangées
- De manière optionnelle, l'authentification du client (mais dans la réalité celle-ci est souvent assurée par la couche applicative)
Pour aller plus loin
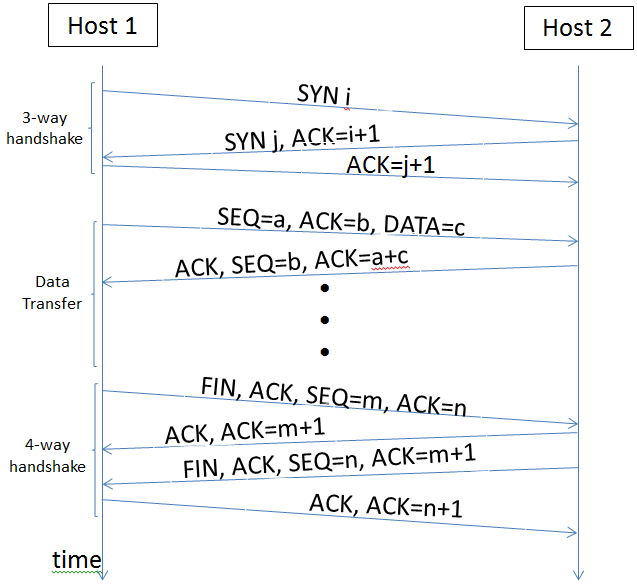
Le protocole HTTP est un membre de la famille TCP/IP. TCP/IP est une famille de protocoles de communication utilisés pour connecter des systèmes informatiques dans un réseau. Il est nommé d'après deux des protocoles de la famille: Transmission Control Protocol (TCP) et Internet Protocol (IP ; oui, comme les IPv4 et IPv6).
Bien que TCP/IP et HTTP ne soient pas parfaitement identiques, le diagramme de séquence suivant permet de mieux comprendre ce qu'il se passe dernière une seule requête HTTP.